Conena
Neues Mitglied
- 50
Hallo liebe Android Gemeinde,
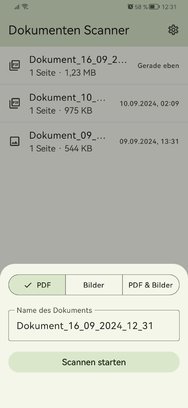
seit geraumer Zeit stört es mich, dass es zwar eine Vielzahl an Dokumenten-Scan Apps für Android gibt, jedoch keine, die einfach, kostengünstig und ohne lästige Accounterstellung arbeitet und dabei sämtliche Verarbeitungsvorgänge lokal durchführt.
Nach der kürzlichen Erweiterung des Machine Learning Kits für Android, sah ich die Gelegenheit, eine App zu entwickeln, die genau diese Anforderungen erfüllt.
Warum solltet Ihr einen Blick auf die App werfen?
Die App richtet sich an Gelegenheitsnutzer, und während es sicherlich Apps gibt, die bessere Ergebnisse liefern, verlangen sie in der Regel einen nicht unerheblichen Preis – sei es in Form von Geld oder Daten. Mein Ziel ist es nicht, mit diesen Apps zu konkurrieren, sondern eine Lösung für den durchschnittlichen Anwender (wie mich selbst) anzubieten.
Feedback
Ich bin offen für euer Feedback und Verbesserungsvorschläge. Beachtet bitte, dass ich am Scanverhalten und den Nachbearbeitungsoptionen nichts ändern werde, da ich hier vollständig auf das ML-Kit von Google setze. Andernfalls wären die Entwicklungskosten zu hoch, um die App kostenlos anzubieten.
Download
Die App kann hier heruntergeladen werden. Sie wurde erst vor zwei Tagen veröffentlicht, daher ist es durchaus möglich, dass noch der ein oder andere Bug vorhanden ist (ich konnte sie aufgrund der Hardwareanforderungen nur auf Android 7 und höher testen, da mir kein Gerät mit 1,7 GB RAM und einer älteren Android-Version zur Verfügung steht). Ich freue mich auf euer Feedback!
Bilder

seit geraumer Zeit stört es mich, dass es zwar eine Vielzahl an Dokumenten-Scan Apps für Android gibt, jedoch keine, die einfach, kostengünstig und ohne lästige Accounterstellung arbeitet und dabei sämtliche Verarbeitungsvorgänge lokal durchführt.
Nach der kürzlichen Erweiterung des Machine Learning Kits für Android, sah ich die Gelegenheit, eine App zu entwickeln, die genau diese Anforderungen erfüllt.
Warum solltet Ihr einen Blick auf die App werfen?
- Kostenfrei
- Benutzerfreundlich
- Zeitgemäßes Design (Material 3/You)
- Kein Account erforderlich
- Keine Werbung
- Keine fragwürdigen Berechtigungen
- 100% lokale Verarbeitung auf dem Gerät
- Nachbearbeitungsmöglichkeiten (z.B. Entfernen von Schatten)
- Geringe Installationsgröße
- Android 5.1+
- Mindestens 1,7 GB RAM
- Aktuelle Google Play Dienste (für die Nutzung des ML-Kits)
Die App richtet sich an Gelegenheitsnutzer, und während es sicherlich Apps gibt, die bessere Ergebnisse liefern, verlangen sie in der Regel einen nicht unerheblichen Preis – sei es in Form von Geld oder Daten. Mein Ziel ist es nicht, mit diesen Apps zu konkurrieren, sondern eine Lösung für den durchschnittlichen Anwender (wie mich selbst) anzubieten.
Feedback
Ich bin offen für euer Feedback und Verbesserungsvorschläge. Beachtet bitte, dass ich am Scanverhalten und den Nachbearbeitungsoptionen nichts ändern werde, da ich hier vollständig auf das ML-Kit von Google setze. Andernfalls wären die Entwicklungskosten zu hoch, um die App kostenlos anzubieten.
Download
Die App kann hier heruntergeladen werden. Sie wurde erst vor zwei Tagen veröffentlicht, daher ist es durchaus möglich, dass noch der ein oder andere Bug vorhanden ist (ich konnte sie aufgrund der Hardwareanforderungen nur auf Android 7 und höher testen, da mir kein Gerät mit 1,7 GB RAM und einer älteren Android-Version zur Verfügung steht). Ich freue mich auf euer Feedback!
Bilder

")